Esta fase del proyecto consistió en levantar la primera fotografía completa de la base transaccional de CT Internacional para definir el alcance real del análisis y detectar problemas estructurales antes de cualquier modelado.
Nota
Sobre los datos en este sitio: las cifras de volumen están publicadas con un nivel de precisión aproximado, los montos monetarios se presentan como índices o en escala log, y las claves de productos están ofuscadas en familias genéricas. Las proporciones, distribuciones, lifts y patrones temporales son auténticos.
1.1 Cifras del universo analizado
Métrica
Valor
Pedidos totales en histórico
~780K
Pedidos en ventana de análisis (30 meses)
~570K
Items transaccionales
~1.8M
Clientes únicos con compras en ventana
18,638
Familias de producto identificadas
908
Periodo cubierto
Dic 2023 — May 2026
La elección de ventana de 30 meses no fue arbitraria. Es lo suficientemente larga para capturar dos ciclos estacionales completos (Buen Fin, cierres fiscales) pero corta como para que no incluyamos comportamiento de clientes que ya no son relevantes para el negocio actual.
2. Tres descubrimientos que cambiaron el rumbo del análisis
2.1 Distribución log-normal extrema del ticket
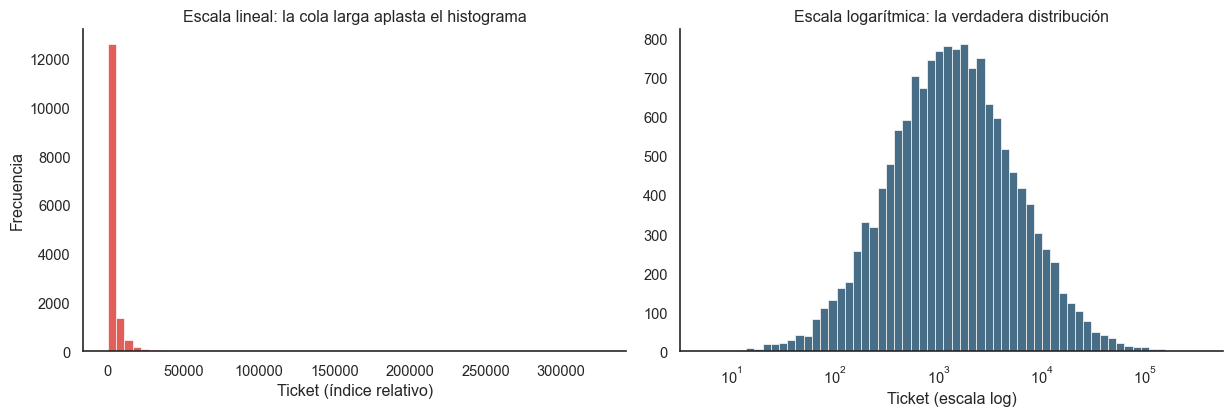
Lo primero que aprendimos al graficar la distribución de pago_total es que el promedio aritmético no significa nada. La mayoría de los tickets son compras pequeñas (consumibles, accesorios), pero existe una cola larga de tickets de infraestructura que arrastra la media hacia arriba de manera engañosa.
Código
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snssns.set_theme(style="white")COLOR_PRIMARY ="#0B3C5D"COLOR_SECONDARY ="#D82822"np.random.seed(42)# Simulación que preserva el comportamiento log-normal realn_orders =15000pago_total = np.random.lognormal(mean=7.2, sigma=1.4, size=n_orders)fig, axes = plt.subplots(1, 2, figsize=(13, 4.5))sns.histplot(pago_total, bins=60, color=COLOR_SECONDARY, edgecolor="white", ax=axes[0])axes[0].set_title("Escala lineal: la cola larga aplasta el histograma")axes[0].set_xlabel("Ticket (índice relativo)")axes[0].set_ylabel("Frecuencia")sns.histplot(pago_total, bins=60, color=COLOR_PRIMARY, edgecolor="white", log_scale=True, ax=axes[1])axes[1].set_title("Escala logarítmica: la verdadera distribución")axes[1].set_xlabel("Ticket (escala log)")axes[1].set_ylabel("")sns.despine()plt.tight_layout()plt.show()
Figura 1: Distribución del ticket en escala lineal vs logarítmica.
El rumbo que nos hizo tomar: este hallazgo definió una de las decisiones técnicas más importantes del proyecto. Antes de cualquier algoritmo de clustering, aplicamos log1p a todas las variables monetarias y de frecuencia. Sin esta transformación, el K-Means quedaría dominado por unos pocos outliers extremos y la segmentación carecería de sentido. Esta decisión vive dentro del pipeline serializado del modelo (no como un paso manual), garantizando que cualquier predicción futura aplique la misma transformación que el entrenamiento.
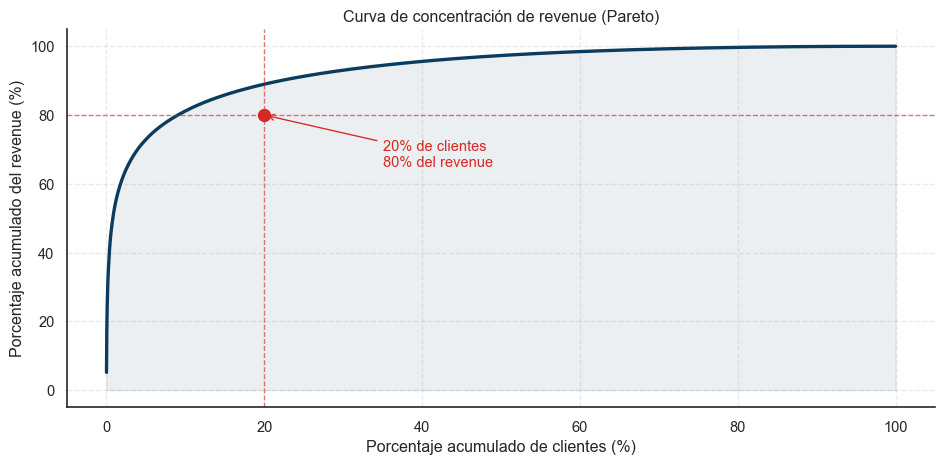
2.2 Concentración del revenue: principio de Pareto
Ordenamos los clientes de mayor a menor según su gasto acumulado en la ventana y graficamos la curva de revenue acumulado.
El rumbo que nos hizo tomar: la concentración de Pareto reforzó la hipótesis de que la segmentación tendría sentido. Si todos los clientes fueran igual de valiosos, agruparlos no agregaría nada. Pero con un 20% de la base generando el 80% del revenue, identificar quiénes son ese 20% y qué los distingue del resto se vuelve la pregunta central del proyecto. Esto también nos llevó a desconfiar de cualquier modelo cuya distribución de clusters fuera muy plana — si el modelo dice “todos los clusters son del 20%”, probablemente no captó la estructura real del negocio.
Advertencia
Nota sobre la concentración real: descubrimos que el top 10 de clientes solo representa ~3.8% del volumen total. Esto sí es Pareto pero no es Pareto extremo: nuestro negocio no depende de un puñado de clientes-llave, sino de una base amplia de clientes valiosos. Esto es importante para entender por qué el segmento MVPs no es “los 10 mejores” sino el cluster con un perfil de comportamiento específico.
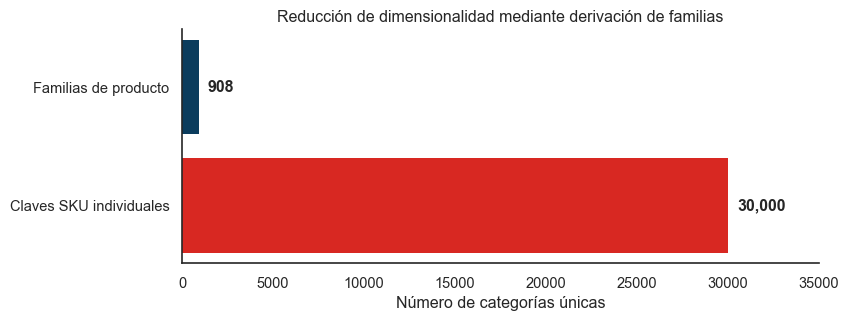
2.3 El problema de las claves: 908 familias en lugar de 30,000 SKUs
Los datos originales identifican cada item por una clave alfanumérica única (por ejemplo, ESDKPK4710). Para los humanos esto es manejable, pero para un algoritmo de Market Basket Analysis es catastrófico: con 30,000 SKUs distintos, casi ninguna regla alcanza el soporte mínimo necesario para considerarse estadísticamente significativa.
La solución fue trivial pero crítica: derivar la “familia” del producto removiendo los dígitos finales de la clave. Con esto, ESDKPK4710, ESDKPK4720 y ESDKPK4730 se agrupan todos bajo la familia ESDKPK.
Código
cardinalidades = pd.DataFrame({'Nivel': ['Claves SKU individuales', 'Familias de producto'],'Cardinalidad': [30000, 908]})fig, ax = plt.subplots(figsize=(9, 3.5))bars = ax.barh(cardinalidades['Nivel'], cardinalidades['Cardinalidad'], color=[COLOR_SECONDARY, COLOR_PRIMARY], edgecolor='none')for bar, val inzip(bars, cardinalidades['Cardinalidad']): ax.text(val +500, bar.get_y() + bar.get_height()/2,f'{val:,}', va='center', fontsize=12, fontweight='bold')ax.set_xlabel('Número de categorías únicas')ax.set_title('Reducción de dimensionalidad mediante derivación de familias')ax.set_xlim(0, 35000)sns.despine()plt.tight_layout()plt.show()
Figura 3: Reducción dramática de cardinalidad: de SKUs únicos a familias.
El rumbo que nos hizo tomar: con 908 familias en lugar de 30,000 SKUs, el MBA pasó de “matemáticamente imposible” a “produce ~3,800 reglas accionables”. Esta es la diferencia entre tener análisis o no tenerlo. La función derivar_familia() quedó como parte del módulo analytics/familia.py del pipeline.
3. Calidad y limpieza de datos
3.1 El cargo financiero CARGO100
Al hacer match entre num_productos de cada orden y el conteo real de items, descubrimos un desfase sistemático: muchas órdenes tenían un item más del que decían. Investigando, identificamos que CARGO100 es el cargo por pago con tarjeta de crédito que se registra como un item dentro de la orden pero no es un producto.
Si se incluye en MBA, contamina los lifts porque aparece en proporciones masivas. Si se incluye en el conteo de productos, infla num_productos por uno en cada orden afectada. La decisión fue:
Filtrar CARGO100 antes de cualquier análisis (segmentación, MBA, temporalidad).
Preservarlo en el parquet histórico porque es información financiera válida.
Recalcular num_productos para que refleje únicamente productos reales.
Esto se aplicó tanto al backfill histórico como al ingest incremental para evitar inconsistencias futuras.
3.2 Validación de calidad sistemática
Decidimos integrar quality checks dentro del pipeline, no como scripts manuales. Por ejemplo:
En la ingesta: el conteo de pedidos no puede disminuir más de un 1% entre corridas (sería señal de un bug en el dedup).
En la segmentación: ningún cluster puede absorber más del 50% (el caso del bug histórico del log-transform mal aplicado, que veremos en la sección de segmentación).
En la temporalidad: la suma de pedidos por segmento debe coincidir exactamente con el conteo en RFM (cross-check). El sistema actual reporta 0.00% de divergencia.
El rumbo que nos hizo tomar: estas validaciones automáticas evitaron varios bugs durante el desarrollo. Por ejemplo, una versión preliminar del pipeline tenía un dedup defectuoso que perdía millones de items; el quality check del cross-check temporalidad-RFM marcó la inconsistencia antes de que llegara a producción.
4. Lo que aprendimos en esta fase
Esta fase parecía rutinaria — “explorar los datos antes de modelar” — pero generó tres de las decisiones más importantes del proyecto entero:
Encapsular el log-transform en el pipeline: porque la distribución log-normal es estructural, no anecdótica.
Trabajar con familias en lugar de SKUs: porque sin esto, el MBA no produce señal.
Filtrar CARGO100 sistemáticamente: porque mezclar cargos financieros con productos contamina cualquier análisis.
Las tres decisiones quedaron codificadas en el pipeline como código, no como notas. Esto significa que cualquier desarrollador futuro las aplica automáticamente sin tener que recordarlas.