El análisis RFM (Recency, Frequency, Monetary) es una técnica clásica de segmentación que evalúa a cada cliente en tres dimensiones:
Recency: días desde la última compra.
Frequency: número de compras en una ventana.
Monetary: valor monetario total de las compras.
La versión heurística clásica asigna puntajes del 1 al 5 en cada dimensión por percentiles y combina los tres en una etiqueta tipo “555 = MVP, 111 = perdido”. Es elegante pero rompe en negocios B2B.
1.1 El problema concreto
Un cliente B2B grande puede comprar dos veces al año, gastando varios cientos de miles cada vez. Para una regla heurística basada en “tiempo desde la última compra”, este cliente se ve como “En Riesgo” si pasaron más de 60 días. Pero matemáticamente, ese cliente está en su ciclo normal.
Castigar a un cliente B2B por una recency alta cuando su cadencia natural es semestral genera dos errores caros:
Falsos positivos: lanzar campañas de retención a clientes que iban a comprar de todas formas, desperdiciando presupuesto.
Falsos negativos: ignorar a clientes recurrentes que de pronto se ralentizan, perdiendo la oportunidad de retenerlos.
El rumbo que nos hizo tomar: necesitábamos una cuarta dimensión que capturara el ritmo natural de cada cliente individualmente. No basta con saber “cuánto tiempo desde la última compra” — necesitamos saber “cuánto tiempo es mucho para este cliente específico”.
2. La cuarta dimensión: cadencia personalizada
2.1 Definición
Para cada cliente con más de una compra, calculamos la mediana de días entre compras consecutivas. Esto es su cadencia personal: el “ritmo vital” de la cuenta.
donde \(\Delta_k\) es la diferencia en días entre la compra \(k\) y la \(k+1\) del cliente \(i\).
Usamos mediana en lugar de media para que un solo retraso inusual no distorsione la métrica.
2.2 El problema de los single-buyers
Hay 3,328 clientes en la base (~17.9% del total) con una sola compra en la ventana. Para ellos, la cadencia es matemáticamente indefinida: no puedes calcular “diferencia entre compras consecutivas” si solo hay una compra.
Dos enfoques posibles:
Eliminarlos: pero son casi una quinta parte de la base, y muchos podrían convertirse en recurrentes.
Imputar un valor razonable: para que el modelo pueda procesarlos.
Elegimos la segunda opción con dos decisiones específicas:
El valor imputado es el percentil 95 de cadencia de los clientes recurrentes (~265 días). Es decir, asumimos por default que un single-buyer es “muy lento” hasta que pruebe lo contrario.
Agregamos un flag binario es_single_buyer para que cualquier análisis posterior pueda separarlos.
Tip
Por qué este diseño: si un single-buyer regresa y se convierte en recurrente, su cadencia se recalcula automáticamente con datos reales. La imputación es solo para “darle un valor mientras tanto” que no rompa el modelo. El flag permite que análisis sensibles (como las alertas de retención) los excluyan explícitamente.
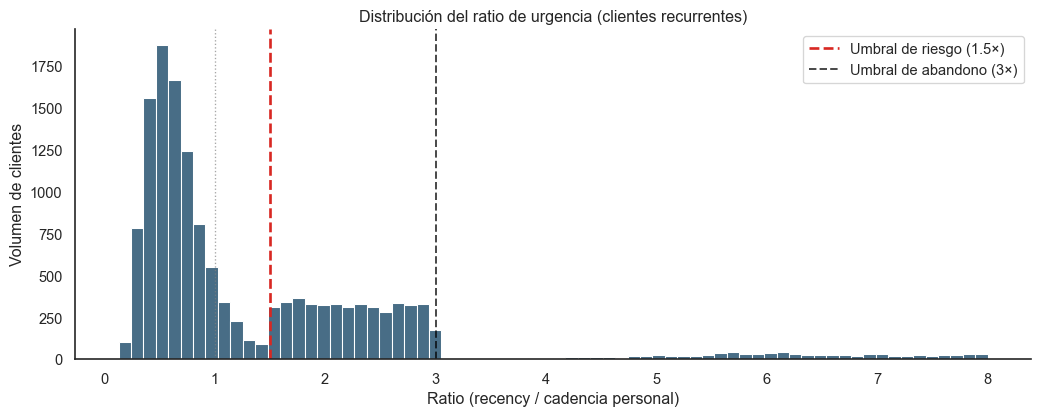
3. El ratio de urgencia
3.1 La métrica
Con cadencia personalizada en mano, podemos construir una métrica que mide qué tan retrasado está cada cliente respecto a su propio ritmo:
\[
\text{ratio de urgencia} = \frac{\text{recency actual}}{\text{cadencia personal}}
\]
Cómo interpretarlo:
Ratio
Significado
< 1.0
El cliente está dentro de su ciclo normal de compra
1.0 - 1.5
Ligeramente retrasado, no es alarma
1.5 - 3.0
Zona de riesgo: el cliente lleva más de 1.5× su cadencia sin comprar
> 3.0
Abandono casi seguro
Código
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snssns.set_theme(style="white")COLOR_PRIMARY ="#0B3C5D"COLOR_WARN ="#D82822"np.random.seed(42)n_recurrentes =15310# 18638 - 3328 single-buyers# Distribución mixta: la mayoría < 1, una cola larga > 1.5n_normales =int(n_recurrentes *0.62)n_riesgo =int(n_recurrentes *0.28)n_abandono = n_recurrentes - n_normales - n_riesgoratios_normales = np.random.lognormal(mean=-0.5, sigma=0.4, size=n_normales)ratios_riesgo = np.random.uniform(1.5, 3.0, size=n_riesgo)ratios_abandono = np.random.lognormal(mean=1.5, sigma=0.6, size=n_abandono) +3.0ratios = np.concatenate([ratios_normales, ratios_riesgo, ratios_abandono])ratios_visual = ratios[ratios <8]plt.figure(figsize=(11, 4.5))sns.histplot(ratios_visual, bins=70, color=COLOR_PRIMARY, edgecolor="white")plt.axvline(x=1.0, color='gray', linestyle=':', linewidth=1, alpha=0.7)plt.axvline(x=1.5, color=COLOR_WARN, linestyle='--', linewidth=2, label="Umbral de riesgo (1.5×)")plt.axvline(x=3.0, color='black', linestyle='--', linewidth=1.5, alpha=0.7, label="Umbral de abandono (3×)")plt.title("Distribución del ratio de urgencia (clientes recurrentes)")plt.xlabel("Ratio (recency / cadencia personal)")plt.ylabel("Volumen de clientes")plt.legend()sns.despine()plt.tight_layout()plt.show()
Figura 1: Distribución del ratio de urgencia en clientes recurrentes.
3.2 Un edge case real: clientes B2B con cadencia cero
Durante el desarrollo descubrimos un cliente B2B legítimo con 6,208 pedidos en 30 meses (~7 pedidos por día). Su cadencia mediana entre compras consecutivas es 0 días porque la mayoría de sus pedidos son del mismo día.
Esto rompe el cálculo del ratio: dividir entre cero da infinito, y matemáticamente cualquier recency > 0 lo marca como abandono. Pero claramente no es un cliente en abandono — es un cliente automatizado de altísima frecuencia.
Solución en el dashboard:
ratio = recency::DOUBLE/GREATEST(dias_entre_compras, 1)
GREATEST(x, 1) trata cualquier cadencia menor a 1 día como si fuera 1. Para este cliente, su ratio efectivo se vuelve igual a su recency en días, lo cual es informativo sin ser engañoso. Adicionalmente, la query de alertas excluye explícitamente clientes con dias_entre_compras < 1:
WHERE segmento IN ('MVPs', 'Alto Valor')AND es_single_buyer =0AND dias_entre_compras >=1AND recency >1.5* dias_entre_compras
El rumbo que nos hizo tomar: los datos del mundo real tienen casos extremos que rompen las fórmulas teóricas. Cualquier métrica derivada (como ratio) debe defenderse contra estos casos en el código, no en el análisis posterior.
4. Las cuatro dimensiones del modelo
Con todo lo anterior, el feature set final para el clustering quedó así:
Feature
Rango típico
Transformación
recency
0 — 900 días
log1p
frequency
1 — 6,200 pedidos
log1p
monetary
1 — varios millones
log1p
dias_entre_compras
0 — 900 días
log1p
Las cuatro pasan por la misma transformación logarítmica + estandarización dentro del pipeline serializado del modelo. Esto garantiza que:
Las distribuciones sesgadas no dominan los algoritmos de distancia.
Las features están en escalas comparables (media 0, desviación 1).
Al guardar el modelo, estas transformaciones viajan con él y se aplican idénticamente en cada predicción futura.
5. Cierre de RFM, antesala del clustering
El RFM clásico fue nuestro punto de partida pero no fue donde nos quedamos. Las decisiones de feature engineering tomadas en esta fase — agregar cadencia, manejar single-buyers, defender contra edge cases — son las que permitieron que el algoritmo de clustering descubriera comportamientos reales y no artefactos estadísticos.
En la siguiente sección documentamos cómo K-Means procesó estas cuatro dimensiones y qué cinco perfiles de cliente emergieron.