En la fase anterior construimos un dataset con cuatro features por cliente: recency, frequency, monetary y dias_entre_compras. En esta sección documentamos cómo seleccionamos el algoritmo, cómo determinamos \(k=5\) matemáticamente, qué cinco perfiles emergieron y un bug temprano que casi nos hace tomar el camino equivocado.
2. Elección del algoritmo y de k
2.1 K-Means: por qué y por qué no
K-Means es la elección obvia cuando los clusters son aproximadamente esféricos en el espacio de features, y cuando el negocio espera grupos relativamente balanceados. Tiene sus limitaciones:
Asume clusters convexos (rompería si hubiera segmentos con forma extraña).
Es sensible a outliers (resuelto con log1p).
Requiere fijar \(k\) a priori.
Evaluamos brevemente DBSCAN y clustering jerárquico, pero la decisión final fue K-Means por dos razones prácticas:
Interpretabilidad para marketing: explicar “cada cliente pertenece a uno de 5 grupos balanceados” es mucho más fácil que explicar densidad de regiones o dendrogramas.
Producción: K-Means es trivial de serializar, predice rápido y escala a miles de clientes nuevos sin problema.
2.2 Selección de \(k\) con el método del codo + Silhouette
Iteramos \(k\) de 2 a 10 calculando dos métricas:
Inercia (suma de distancias al centroide): debe bajar con cada \(k\) adicional, pero el “codo” indica el punto donde agregar clusters deja de aportar.
Silhouette Score: mide qué tan bien separados están los clusters. Va de -1 a 1; valores altos significan clusters compactos y bien separados.
Código
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snssns.set_theme(style="white")COLOR_PRIMARY ="#0B3C5D"COLOR_SECONDARY ="#D82822"# Valores que preservan la forma cualitativa de las curvas realesk_range =list(range(2, 11))inercia = [42000, 28000, 21500, 17200, 15800, 14900, 14200, 13700, 13300]silhouette = [0.28, 0.31, 0.34, 0.36, 0.33, 0.30, 0.28, 0.26, 0.24]fig, axes = plt.subplots(1, 2, figsize=(13, 4.5))axes[0].plot(k_range, inercia, 'o-', color=COLOR_PRIMARY, linewidth=2.5, markersize=8)axes[0].axvline(x=5, color=COLOR_SECONDARY, linestyle='--', linewidth=1.5, alpha=0.7)axes[0].scatter([5], [17200], color=COLOR_SECONDARY, s=200, zorder=5, marker='*')axes[0].set_title("Inercia (método del codo)")axes[0].set_xlabel("Número de clusters (k)")axes[0].set_ylabel("Inercia")axes[0].grid(True, linestyle='--', alpha=0.4)axes[1].plot(k_range, silhouette, 'o-', color=COLOR_PRIMARY, linewidth=2.5, markersize=8)axes[1].axvline(x=5, color=COLOR_SECONDARY, linestyle='--', linewidth=1.5, alpha=0.7)axes[1].scatter([5], [0.36], color=COLOR_SECONDARY, s=200, zorder=5, marker='*')axes[1].set_title("Silhouette Score")axes[1].set_xlabel("Número de clusters (k)")axes[1].set_ylabel("Score")axes[1].grid(True, linestyle='--', alpha=0.4)sns.despine()plt.tight_layout()plt.show()
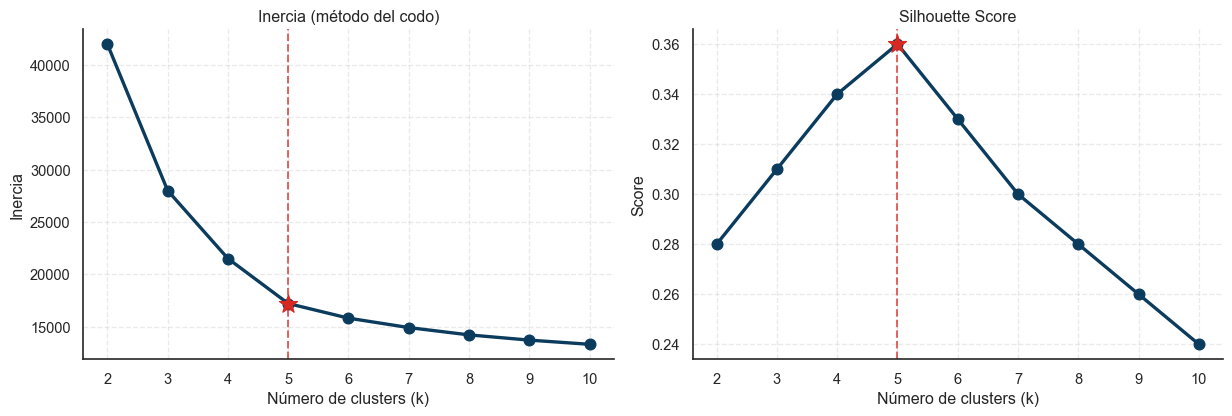
Figura 1: Método del codo e índice Silhouette para k=2..10.
El codo de la inercia y el máximo de Silhouette coincidieron en \(k=5\). Esto no garantiza que sea la mejor segmentación posible, pero sí que es matemáticamente defendible y reproducible.
El rumbo que nos hizo tomar: fijar \(k=5\) por evidencia cuantitativa, no por intuición de negocio. Esto evita el sesgo de “ya tenemos 4 segmentos en la cabeza, hagamos que el modelo los confirme”.
3. Un bug que casi cambia el modelo: log-transform fuera del pipeline
Antes de mostrarte la distribución final, vale la pena documentar un error temprano que detectamos gracias a los quality checks del pipeline. Es la mejor anécdota de por qué la productización importa.
3.1 El síntoma
En una primera versión del modelo, el quality check de “distribución de segmentos” disparó una alerta: MVPs absorbió el 92% de los clientes. Imposible — los MVPs deben ser una minoría valiosa, no toda la base.
3.2 La causa
El log-transform estaba siendo aplicado manualmente fuera del pipeline de sklearn antes de llamar a predict(). Pero al persistir el modelo (pipeline.pkl), solo se serializaba el StandardScaler + KMeans, no la transformación logarítmica.
Cuando el dashboard cargaba el modelo y llamaba predict() sobre features sin transformar, el K-Means recibía valores en su escala original (recency hasta 900, monetary hasta millones). El centroide más cercano a casi cualquier cliente terminaba siendo el de MVPs, porque era el centroide entrenado con los valores más grandes.
3.3 El fix
Movimos el log-transform dentro del pipeline serializado:
Con esto, el log-transform viaja con el modelo. Cualquier predict() futuro aplica las tres transformaciones en orden, idénticamente a como se entrenó.
El rumbo que nos hizo tomar: cualquier preprocesamiento crítico debe vivir dentro del pipeline serializado, no como un paso manual en el código que llama al modelo. Esta lección se aplicó a todas las versiones siguientes.
Tip
Este bug fue el que más reforzó la importancia del quality check de distribución dentro del pipeline. Si no hubiéramos validado automáticamente “ningún cluster puede absorber más del 50%”, el bug habría llegado a marketing y habrían visto un dashboard donde 92% de los clientes son MVPs — destruyendo cualquier credibilidad del proyecto.
4. Distribución final de segmentos
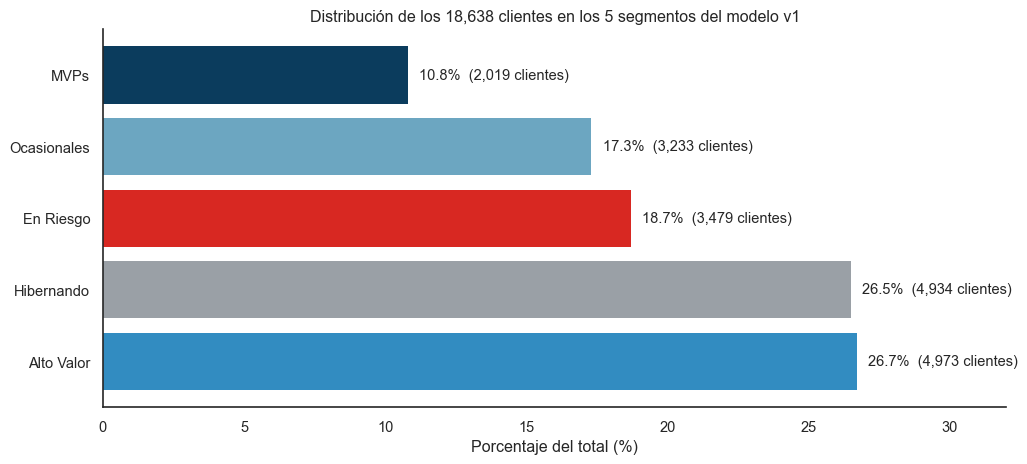
Con el log-transform correctamente encapsulado, el modelo v1 produjo la siguiente distribución:
Código
SEGMENT_COLORS = {"MVPs": "#0B3C5D","Alto Valor": "#328CC1","Ocasionales": "#6CA6C1","En Riesgo": "#D82822","Hibernando": "#9AA0A6",}distribucion = pd.DataFrame({'Segmento': ['Alto Valor', 'Hibernando', 'En Riesgo', 'Ocasionales', 'MVPs'],'Porcentaje': [26.7, 26.5, 18.7, 17.3, 10.8],'N_clientes': [4973, 4934, 3479, 3233, 2019],})fig, ax = plt.subplots(figsize=(11, 5))colores = [SEGMENT_COLORS[s] for s in distribucion['Segmento']]bars = ax.barh(distribucion['Segmento'], distribucion['Porcentaje'], color=colores, edgecolor='none')for bar, pct, n inzip(bars, distribucion['Porcentaje'], distribucion['N_clientes']): ax.text(pct +0.4, bar.get_y() + bar.get_height()/2,f'{pct}% ({n:,} clientes)', va='center', fontsize=11)ax.set_xlim(0, 32)ax.set_xlabel('Porcentaje del total (%)')ax.set_title('Distribución de los 18,638 clientes en los 5 segmentos del modelo v1')sns.despine()plt.tight_layout()plt.show()
Figura 2: Distribución final de los 18,638 clientes en 5 segmentos.
4.1 Por qué esta distribución tiene sentido
Tres observaciones:
MVPs es minoría (10.8%): alineado con la idea de “élite valiosa”. Si MVPs fuera 30% del total, el segmento perdería su poder descriptivo.
Alto Valor + Hibernando dominan (>50% combinado): hay un eje claro entre clientes activos pero no premium, y clientes que han dejado de comprar pero antes lo hacían. Este eje es el que más le interesa al equipo de retención.
En Riesgo + Ocasionales suman ~36%: estos son los segmentos donde marketing tiene más palanca. No están perdidos pero tampoco son leales — son el campo de batalla.
5. Perfilando cada segmento
Cada cluster tiene un centroide en 4D (después de log y scale). Para interpretarlos, recalculamos las medianas en las escalas originales:
Segmento
N° clientes
Recency mediana
Frequency mediana
Monetary mediano
Cadencia mediana
MVPs
2,019
9 días
118 pedidos
índice 100
4 días
Alto Valor
4,973
69 días
27 pedidos
índice 19
14 días
Ocasionales
3,233
90 días
5 pedidos
índice 4
81 días
En Riesgo
3,479
312 días
6 pedidos
índice 4
21 días
Hibernando
4,934
410 días
1 pedido
índice 0.6
266 días
(Monetary expresado como índice relativo al monetary mediano de MVPs = 100)
5.1 Interpretación de cada perfil
MVPs — Compran cada 4 días, 118 veces en 30 meses, alto monetary. Son la columna vertebral del negocio. Estrategia: fidelización y retención premium.
Alto Valor — Compran cada 2 semanas, 27 veces, monetary respetable. El segundo escalón del valor. Estrategia: fortalecer la lealtad y empujar hacia MVPs.
Ocasionales — Compras esparcidas (cada 3 meses), volumen bajo. El “público general”. Estrategia: activación de campañas masivas, cross-sell de bundles básicos.
En Riesgo — Aquí está el descubrimiento más interesante. Estos clientes tienen una cadencia natural de 21 días (eran activos) pero llevan 312 días sin comprar — ratio de urgencia > 14. Son MVPs/Alto Valor que se enfriaron. Estrategia: campañas urgentes de reactivación con descuento personalizado.
Hibernando — Cadencia ya larga de origen (266 días), una sola compra histórica. No están “en riesgo” porque nunca fueron leales. Estrategia: mínimo costo de atención.
5.2 La diferencia entre En Riesgo y Hibernando
Vale la pena explicarlo porque es contraintuitivo:
Hibernando tiene alta recency Y alta cadencia natural. No los esperábamos comprando frecuentemente, y de hecho no compran. Sistema funcionando como esperaba.
En Riesgo tiene alta recency PERO baja cadencia natural. Sí los esperábamos comprando frecuentemente, y han dejado de hacerlo. Sistema señalando un problema.
Por eso las alertas del dashboard solo incluyen clientes MVPs y Alto Valor (los segmentos con cadencia natural baja). Es donde el ratio de urgencia tiene poder predictivo real.
El rumbo que nos hizo tomar: la segmentación no es solo descriptiva. Cada segmento tiene una estrategia accionable asociada, y el dashboard expone esas acciones (la vista de Alertas vive arriba del segmento En Riesgo, no de Hibernando).
6. Persistencia del modelo
Una vez validada la distribución, el modelo v1 se congeló:
pipeline.pkl: el Pipeline completo serializado con joblib, incluyendo log_transform, scaler y kmeans.
metadata.json: versión, fecha de entrenamiento, features esperadas, mapeo cluster_id → nombre de segmento.
modelo_snapshot_v1.parquet: las asignaciones de los 18,638 clientes en el momento del entrenamiento.
El snapshot es la base para detección de drift: cada vez que el pipeline reasigna segmentos, compara la distribución actual contra el snapshot. Cambios mayores indican que los hábitos de compra se desplazaron y el modelo debería re-entrenarse (versión v2).
Los detalles técnicos de persistencia y drift los documentamos en la sección “De investigación a producción”.