Hasta este punto del proyecto, todo vivía en notebooks: análisis exploratorios, RFM, K-Means, MBA y estacionalidad. Esto está bien para descubrir patrones, pero no es operativo. Si marketing necesita los resultados, alguien tiene que abrir Jupyter, recordar el orden de las celdas, ejecutarlas, exportar gráficas y mandarlas por correo. Esa fricción mata cualquier adopción.
La fase de productización consistió en cerrar esa brecha. El resultado es Pulse: una plataforma operativa que corre todos los días, mantiene los datos frescos y expone los resultados como un servicio web que cualquier persona del equipo de marketing puede abrir en su navegador. Esta sección documenta cómo se construyó.
Tip
Tres principios que orientaron toda la productización:
Lo crítico vive en código, no en notas: cada decisión técnica (filtros, transformaciones, ventanas) está codificada con tests que la protegen.
El sistema debe operar sin desarrollador: cron + systemd + quality checks automáticos.
Cualquier cambio debe ser auditable: el snapshot del modelo congelado nos permite saber si las predicciones de hoy coinciden con las de hace 6 meses.
2. Persistencia del modelo: MLOps minimalista
2.1 Por qué congelar el modelo
Un error común en proyectos analíticos es re-entrenar el modelo cada vez que se ejecuta. Esto tiene varias consecuencias graves:
Las predicciones cambian sin control: un cliente puede ser MVP en marzo y En Riesgo en abril sin que su comportamiento haya cambiado, solo porque el K-Means reinicializó sus centroides.
No hay auditoría: ¿por qué la distribución de hoy es distinta a la del mes pasado? Imposible saber si fue el modelo o los datos.
Marketing pierde confianza: nadie quiere segmentar audiencias sobre algo que cambia bajo sus pies.
La solución es congelar el modelo en un artefacto serializable y aplicarlo idénticamente en cada predicción futura.
2.2 La clase wrapper SegmentadorClientes
Construimos un wrapper de scikit-learn que encapsula:
log_transform — Suaviza las distribuciones sesgadas (recordá la sección de EDA).
scaler — Estandariza para que las cuatro features estén en escalas comparables.
kmeans — Asigna a cada cliente uno de los 5 clusters.
Lo crítico es que las tres transformaciones viajan juntas. Cuando guardamos el pipeline con joblib.dump(), el log-transform queda dentro del archivo .pkl. Esto previene el bug histórico que documentamos en la sección de Segmentación (donde el log vivía fuera y MVPs absorbió el 92%).
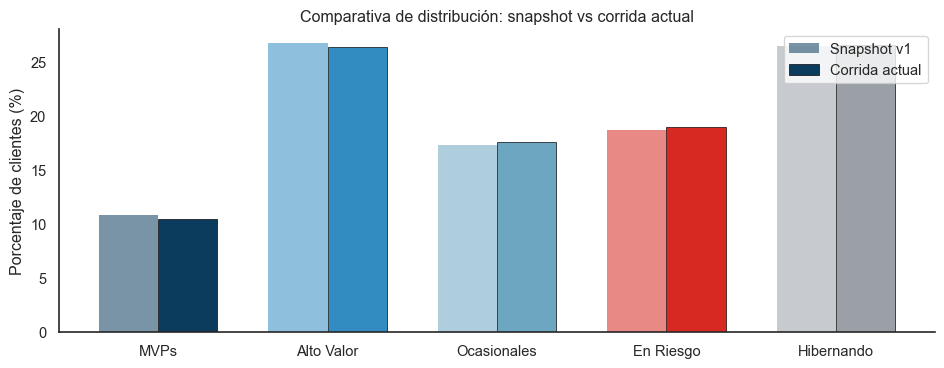
modelo_snapshot_v1.parquet contiene las asignaciones exactas de los 18,638 clientes en el momento del entrenamiento. Es la base para el control de drift que documentamos abajo.
2.4 Control de drift por snapshot
Los hábitos de compra cambian con el tiempo (concept drift). Un modelo entrenado en 2025 puede dejar de ser representativo en 2026 si el negocio cambia significativamente.
Para detectar esto sin re-entrenar a ciegas, comparamos cada nueva corrida del pipeline contra el snapshot original:
Código
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snssns.set_theme(style="white")SEGMENT_COLORS = {"MVPs": "#0B3C5D","Alto Valor": "#328CC1","Ocasionales": "#6CA6C1","En Riesgo": "#D82822","Hibernando": "#9AA0A6",}# Snapshot original (v1) vs corridas posteriores con drift simuladosnapshot = {'MVPs': 10.8, 'Alto Valor': 26.7, 'Ocasionales': 17.3, 'En Riesgo': 18.7, 'Hibernando': 26.5}corrida_hoy = {'MVPs': 10.4, 'Alto Valor': 26.4, 'Ocasionales': 17.6, 'En Riesgo': 19.0, 'Hibernando': 26.6}df_drift = pd.DataFrame({'Segmento': list(snapshot.keys()),'Snapshot v1 (%)': list(snapshot.values()),'Corrida actual (%)': list(corrida_hoy.values()),})df_drift['Diferencia (pp)'] = df_drift['Corrida actual (%)'] - df_drift['Snapshot v1 (%)']fig, ax = plt.subplots(figsize=(10, 4))x = np.arange(len(df_drift))width =0.35colores_seg = [SEGMENT_COLORS[s] for s in df_drift['Segmento']]ax.bar(x - width/2, df_drift['Snapshot v1 (%)'], width, color=colores_seg, alpha=0.55, edgecolor='none', label='Snapshot v1')ax.bar(x + width/2, df_drift['Corrida actual (%)'], width, color=colores_seg, edgecolor='black', linewidth=0.5, label='Corrida actual')ax.set_xticks(x)ax.set_xticklabels(df_drift['Segmento'])ax.set_ylabel("Porcentaje de clientes (%)")ax.set_title("Comparativa de distribución: snapshot vs corrida actual")ax.legend(loc='upper right')ax.axhline(y=0, color='black', linewidth=0.5)sns.despine()plt.tight_layout()plt.show()
Figura 1: Detección de drift por comparación contra snapshot original.
El sistema lo registra automáticamente en cada corrida monthly. Si la diferencia en cualquier segmento supera un umbral (hoy 5 puntos porcentuales), el log marca una alerta. La acción humana es decidir si entrenar un modelo v2.
El rumbo que nos hizo tomar: este control de drift es la diferencia entre un modelo que “funciona hoy” y un modelo en producción real. Sin él, el modelo v1 podría seguir produciendo segmentaciones tres años después aunque los hábitos cambiaron radicalmente, y nadie se daría cuenta hasta que marketing reportara “estas alertas ya no tienen sentido”.
Nota
Por qué no usamos MLFlow desde el inicio: MLFlow es excelente cuando tienes múltiples modelos en juego, tracking de runs, y un equipo experimentando en paralelo. Para un único modelo congelado con snapshot, agregaría infraestructura (servidor MLFlow, registry, UI) sin valor inmediato. La decisión es introducir MLFlow cuando lleguen más modelos (forecasting, CLV) — está documentado en “Visión y futuro”.
3. Pipeline ETL modular
3.1 La necesidad
Los notebooks ejecutaban el ciclo completo: extraer datos, calcular RFM, segmentar, generar MBA, agregados temporales. Pero los notebooks tienen varios problemas para producción:
Orden frágil: si ejecutas una celda fuera de orden, los resultados se rompen silenciosamente.
Estado oculto: variables del kernel pueden quedar de ejecuciones anteriores.
No testeable: no hay forma de validar que un cambio en RFM no rompa el MBA.
Difícil de orquestar: ejecutar diariamente requiere intervención manual.
La solución fue refactorizar todo en módulos Python con responsabilidades claras y orquestarlos desde un runner.
3.2 Arquitectura por capas
Código
flowchart TD A[MongoDB] -->|ingest incremental| B[etl/ingest.py] B -->|orders_historicos.parquet<br/>items_historicos.parquet| C[runner.py] C --> D[analytics/familia.py] D --> E[analytics/rfm.py] E --> F[analytics/segmentacion.py] F --> G[analytics/mba.py] F --> H[analytics/temporalidad.py] F -->|clientes_segmentados.parquet| O[7 parquets outputs] G -->|mba_*.parquet| O H -->|temp_*.parquet| O M[models/v1/<br/>pipeline.pkl] -.->|load + predict| F V[pipeline/validacion.py] -.->|quality checks| C style A fill:#e3f2fd style M fill:#fff3e0 style O fill:#e8f5e9 style V fill:#fce4ec
flowchart TD
A[MongoDB] -->|ingest incremental| B[etl/ingest.py]
B -->|orders_historicos.parquet<br/>items_historicos.parquet| C[runner.py]
C --> D[analytics/familia.py]
D --> E[analytics/rfm.py]
E --> F[analytics/segmentacion.py]
F --> G[analytics/mba.py]
F --> H[analytics/temporalidad.py]
F -->|clientes_segmentados.parquet| O[7 parquets outputs]
G -->|mba_*.parquet| O
H -->|temp_*.parquet| O
M[models/v1/<br/>pipeline.pkl] -.->|load + predict| F
V[pipeline/validacion.py] -.->|quality checks| C
style A fill:#e3f2fd
style M fill:#fff3e0
style O fill:#e8f5e9
style V fill:#fce4ec
Cada flecha es un input/output explícito. Cada módulo es testeable independientemente con su propia suite de pytest.
3.3 Los tres modos de ejecución
El runner expone tres modos según la frecuencia del trabajo:
Modo
Pasos ejecutados
Duración típica
Cuándo
daily
ingest → segmentación → temporalidad
~30s
Cron diario (3am). MBA solo si no existe.
weekly
daily + recálculo completo de MBA
~45s
Manual semanal o cuando se quiere actualizar reglas.
monthly
weekly + validación de drift
~60s
Manual mensual para auditar el modelo.
La justificación de tener modos separados es costo computacional. El MBA es el paso más caro del pipeline (FP-Growth sobre miles de canastas por segmento). Recalcularlo todos los días no agrega valor — las reglas de asociación no cambian materialmente en 24 horas. En cambio, los segmentos de clientes sí cambian (alguien puede pasar de Alto Valor a En Riesgo en un día), así que la segmentación corre diaria.
3.4 Ingest incremental con watermark
La fuente de datos es MongoDB. La primera corrida hace backfill completo (~780K pedidos). Las corridas posteriores usan un watermark (timestamp del último pedido procesado) para extraer solo los nuevos:
Este patrón evita re-extraer el universo completo en cada corrida, lo cual sería catastrófico para la BD de origen y absurdamente lento.
Advertencia
Bug histórico: una versión preliminar del dedup usaba solo order_id como clave. Esto eliminaba millones de items porque un mismo pedido tiene muchos items con el mismo order_id. El fix fue usar la clave compuesta(order_id, clave_producto) para deduplicación de items. El quality check de “el conteo de items no debe disminuir más de 1%” detectó el bug antes de llegar a producción.
3.5 Quality checks: el sistema de defensa
En cada paso del runner se ejecutan validaciones automáticas que disparan si algo se ve raro:
El sistema actual reporta 0.00% en el cross-check en cada corrida. Esto significa que cualquier número de la vista de Estacionalidad es perfectamente consistente con la vista de Overview — invariante validado automáticamente.
4. El dashboard Pulse
4.1 Diseño general
El dashboard es una aplicación web construida con un stack ligero:
Capa
Componente
Justificación
Backend
FastAPI
Endpoints async, validación automática de inputs, soporte nativo de OpenAPI.
Motor SQL
DuckDB
Lee parquets directamente sin cargar todo en memoria; SQL completo; embebido (cero ops).
Frontend
Jinja2 + Plotly.js
Templates HTML server-side; gráficas interactivas client-side.
Servidor
Uvicorn
ASGI estándar para FastAPI.
No usamos React, Vue ni un frontend SPA porque la complejidad no se justifica. Cada vista es una página HTML con un payload initial_data embebido para evitar fetches en la primera pintura. Cuando el usuario interactúa con filtros, JavaScript hace fetch a endpoints /api/* y Plotly actualiza las gráficas.
4.2 Siete vistas, una para cada pregunta
Código
import pandas as pdvistas = pd.DataFrame({'Vista': ['Overview', 'Bundles', 'Estacionalidad', 'Comparador','Heatmap Bundles', 'Alertas', 'Cliente'],'Pregunta de negocio': ['¿Cómo está distribuida nuestra base de clientes?','¿Qué productos puedo agrupar y a quién?','¿Cuándo lanzar campañas?','¿Cómo se diferencian dos segmentos?','¿Cuándo se venden los bundles principales?','¿Qué clientes valiosos están en riesgo?','¿Quién es este cliente específico?', ],'Output del pipeline consumido': ['clientes_segmentados','mba_accionables + mba_por_segmento','temp_hora_dia + temp_mensual','clientes_segmentados + mba_accionables','temp_bundles','clientes_segmentados','clientes_segmentados + orders + items', ],})vistas
Tabla 1: Las siete vistas del dashboard y su pregunta de negocio.
Vista
Pregunta de negocio
Output del pipeline consumido
0
Overview
¿Cómo está distribuida nuestra base de clientes?
clientes_segmentados
1
Bundles
¿Qué productos puedo agrupar y a quién?
mba_accionables + mba_por_segmento
2
Estacionalidad
¿Cuándo lanzar campañas?
temp_hora_dia + temp_mensual
3
Comparador
¿Cómo se diferencian dos segmentos?
clientes_segmentados + mba_accionables
4
Heatmap Bundles
¿Cuándo se venden los bundles principales?
temp_bundles
5
Alertas
¿Qué clientes valiosos están en riesgo?
clientes_segmentados
6
Cliente
¿Quién es este cliente específico?
clientes_segmentados + orders + items
Cada vista responde a una pregunta concreta de negocio. Esto es intencional: pulse no es un “dashboard de exploración” donde marketing tiene que armar sus propios filtros. Es un conjunto de herramientas operativas con propósito definido.
4.3 Tres decisiones de UX que valieron la pena
(a) Vista marketing vs vista exploratoria en Bundles
En la vista de Bundles, ofrecemos un toggle entre “Vista marketing” (solo reglas 1→1 y 1→2 con revenue) y “Vista exploratoria” (todas las reglas, sin revenue). Esto resuelve un trade-off real:
Marketing necesita reglas operativas (fáciles de comunicar) con impacto monetario estimado.
Analistas necesitan ver todas las reglas, incluyendo multi-producto complejas.
Antes de este toggle, teníamos una sola tabla que mezclaba ambos casos. Marketing se confundía con reglas tipo {A, B, C} → {D, E}, y los analistas no podían explorar a profundidad. El toggle separó las dos audiencias sin duplicar código.
(b) Cuadrantes con mediana dinámica
El Market Basket Opportunity Map (sección 5 de MBA) divide el plano en cuatro cuadrantes usando la mediana de confidence y lift. Esta decisión es preferible a usar umbrales fijos porque:
Las medianas se recalculan al cambiar filtro, garantizando división balanceada visualmente.
Marketing no tiene que “saber qué umbral usar” — los cuadrantes siempre tienen un volumen razonable de reglas.
(c) Ratio de urgencia defendido contra cadencia cero
Documentado en la sección de RFM, pero vale repetir: el query de alertas usa GREATEST(dias_entre_compras, 1) y excluye dias_entre_compras < 1. Esto evita que un cliente B2B automatizado aparezca con ratio infinito. Es un caso edge real que vivimos.
4.4 Pipeline → dashboard: el contrato de los 7 parquets
El dashboard no se conecta a MongoDB. Solo lee Parquets. Esto es deliberado:
Latencia: las queries SQL sobre Parquet con DuckDB tardan milisegundos. Conectarse a MongoDB introduciría latencia variable.
Aislamiento: si MongoDB se cae, el dashboard sigue funcionando con los últimos parquets generados.
Reproducibilidad: el dashboard de hoy muestra exactamente lo que el pipeline generó la última vez. No hay deriva entre datos vistos en el dashboard y datos analizados.
El contrato entre pipeline y dashboard son los siete parquets generados en datos/processed/:
DuckDB los registra como vistas SQL con nombres estables (segmentos, orders, mba_accionables, etc.). Las queries en queries.py consultan estas vistas usando parámetros (nunca interpolación de strings, para evitar SQL injection).
5. El deployment final
El dashboard corre como un servicio supervisado en un servidor on-premise AlmaLinux 9. Los detalles operativos completos están en la sección de Documentación Técnica, pero el resumen es:
Componente
Configuración
Sistema operativo
AlmaLinux 9.4
Modo SELinux
Permissive
Firewall
firewalld con puerto custom abierto
Supervisión
systemd con Restart=always
Ingest
Cron a las 3am todos los días
Acceso
URL interna de la intranet, sin HTTPS (intranet)
Tests
60+ pytest, ejecución manual antes de merge
El test de robustez crítico fue reboot del servidor: después de reiniciar, ¿el dashboard vuelve solo? La respuesta es sí — systemd lo levanta automáticamente cuando la red está disponible. Marketing puede entrar al dashboard sin que un desarrollador haya intervenido.
6. La métrica final: ¿se usa?
La pregunta de oro para cualquier proyecto de productización es ¿se usa?. Las métricas técnicas (uptime, latencia, accuracy) son condiciones necesarias pero no suficientes.
A la fecha de este escrito:
El pipeline corre exitosamente todos los días sin intervención.
El dashboard está disponible en la intranet con uptime alto.
La fase de validación con marketing está en curso (siguiente paso documentado en “Visión y futuro”).
Cuando marketing reporte que abandonan una reunión de planeación abriendo Pulse en lugar de pedir reportes ad-hoc, sabremos que la productización tuvo éxito real.